一、实验目的 掌握常用的排序方法,并掌握C语言实现排序算法的方法;了解各种排序方法过程及依据原则,并掌握各种排序方法的时间复杂度和稳定性的分析方法。
二、实验原理 参照课本p.220, Figure7.2;p.223,Figure7.4;p.228,Figure7.8;p.232-233, Figure7.9-7.10; p240-243, Figure 7.12-7.15.
三、实验内容 统计成绩
【问题描述】
给出n个学生的考试成绩表,每条信息由姓名和分数组成,利用排序算法完成以下任务:
① 按照分数高低次序,打印出每个学生在考试中获得的名次,分数相同的为同一名次。
②按照名次列出每个学生的姓名和分数。
【要求】学生的考试成绩需要从键盘输入数据建立,同时要设计输出格式。
四、实验要求 能够采用常用的排序算法中的一种实现以上两个任务;
五、实验源程序 SortScore.h 头文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #ifndef _SortScore_H struct StudentScore ;typedef struct StudentScore *StudentList ;typedef struct StudentScore *Position ;StudentList MakeEmpty () ; void ListOrder (StudentList L,float X,char S[20 ]) ; Position FindNode (StudentList L,int node) ; Position FindPreviousPosition (StudentList L, Position P) ; void InsertionSort (StudentList L) ; void ShellSort (StudentList L) ; void PrintList (StudentList L) ; #endif
SortScore.c 主程序文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 #include "SortScore.h" #include <stdio.h> #include <string.h> Position pin; int nodenum = 1 ;struct StudentScore { char name[20 ]; float score; int node; Position next; }; StudentList MakeEmpty () { StudentList L= (StudentList)malloc (sizeof (struct StudentScore)); L->score = 0 ; strcpy_s(L->name,strlen ("Null" )+1 ,"Null" ); L->next = NULL ; L->node = nodenum; nodenum++; return L; } void ListOrder (StudentList L,float X,char S[20 ]) { if (strcmp (L->name,"Null" )==0 ) { strcpy_s(L->name,strlen (S)+1 ,S); L->score = X; } else { Position p2=(Position)malloc (sizeof (struct StudentScore)); pin->next = p2; p2->score = X; strcpy_s(p2->name,strlen (S)+1 ,S); p2->next = NULL ; p2->node = nodenum; pin = p2; nodenum++; } } Position FindNode (StudentList L,int node) { while (L->node!=node) L = L->next; return L; } Position FindPreviousPosition (StudentList L, Position P) { while (P->node-L->node!=1 ) L = L->next; return L; } void InsertionSort (StudentList L) { float temp; char strtmp[20 ]; Position P1; StudentList TemCell; for (TemCell = L->next;TemCell!=NULL ;TemCell=TemCell->next) { strcpy_s(strtmp,strlen (TemCell->name)+1 ,TemCell->name); temp = TemCell->score; for (P1 = TemCell;(P1!=L)&&(FindPreviousPosition(L,P1)->score<temp);P1 = FindPreviousPosition(L,P1)) { P1->score = FindPreviousPosition(L,P1)->score; strcpy_s(P1->name,strlen (FindPreviousPosition(L,P1)->name)+1 ,FindPreviousPosition(L,P1)->name); } P1->score = temp; strcpy_s(P1->name,strlen (strtmp)+1 ,strtmp); } } void ShellSort (StudentList L) { int increment,j; float temp; char strtmp[20 ]; Position PTemp,PTemp1; StudentList TemCell; for (increment = (nodenum-1 )/2 ;increment > 0 ;increment/=2 ) for (int i = increment+1 ;i<nodenum;i++) { PTemp = FindNode(L,i); temp = PTemp->score; strcpy_s(strtmp,strlen (PTemp->name)+1 ,PTemp->name); for (j = i;j>increment;j-=increment) { PTemp1 = FindNode(L,j-increment); if (temp>PTemp1->score) { FindNode(L,j)->score = PTemp1->score; strcpy_s(FindNode(L,j)->name,strlen (PTemp1->name)+1 ,PTemp1->name); } else break ; } FindNode(L,j)->score = temp; strcpy_s(FindNode(L,j)->name,strlen (strtmp)+1 ,strtmp); } } void PrintList (StudentList L) { Position P = L; printf ("排名\t\t姓名\t\t成绩\n" ); do { printf ("%d\t\t%s\t\t%.1f\n" , P->node,P->name,P->score); P = P->next; } while (P != NULL ); printf ("学生人数为:%d\n" , nodenum-1 ); } int main (void ) { int n; StudentList StudentStart = MakeEmpty(); pin = StudentStart; while (1 ) { int stunum; float stuscore; char stuname[20 ]; printf ("请选择需要进行的操作:1.输入学生成绩 2.输出学生成绩排名 3.插入排序 4.希尔排序\n" ); scanf_s("%d" , &n); switch (n) { case 1 : printf ("请输入录入成绩人数:" ); scanf_s("%d" , &stunum); printf ("\n" ); for (int i = 0 ; i <stunum;i++) { printf ("请输入学生%d姓名:" ,i+1 ); scanf_s("%s" , stuname,sizeof (stuname)); printf ("\n" ); printf ("请输入%s的成绩:" ,stuname); scanf_s("%f" ,&stuscore); ListOrder(StudentStart,stuscore,stuname); printf ("\n" ); } printf ("录入结束!\n" ); break ; case 2 : PrintList(StudentStart); break ; case 3 : InsertionSort(StudentStart); printf ("插入排序完成!\n" ); break ; case 4 : ShellSort(StudentStart); printf ("希尔排序完成!\n" ); } } }
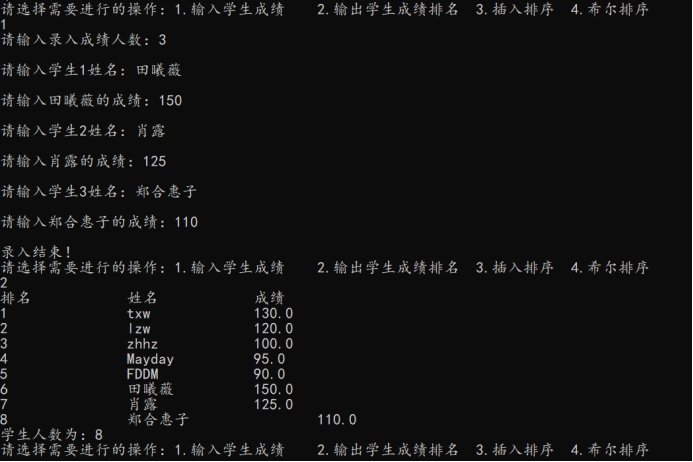
六、实验结果 做了一个交互的程序,用户可以自己选择要执行的操作:
结果可见,输入数据存储正确,打印显示学生姓名、排名、成绩正常(未排序前)
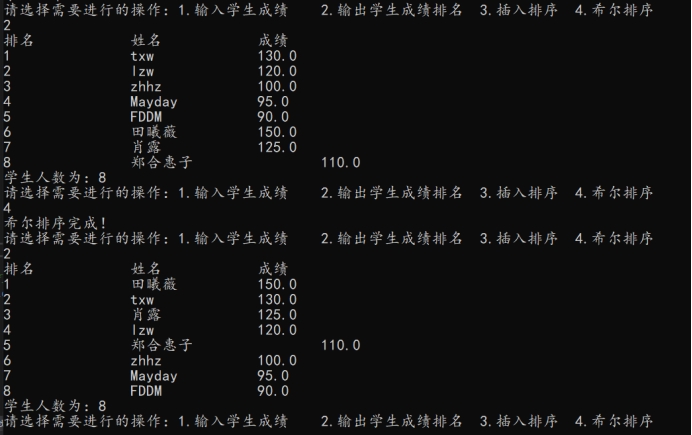
执行插入排序:
插入排序功能正常
由于采用的是动态链表录入成绩信息,可以在中间继续输入学生成绩:
录入成功(未进行排序显示)
根据当前动态链表继续使用希尔排序完成排序:
希尔排序功能正常。
七、实验心得 插入排序 假设有一数组a[10]需要进行插入排序(以升序为例):
从a[1]开始,开始比较前将a[1]数据备份到temp,再开始进行比较:若a[0]>temp,则执行
a[1] = a[0]; a[0] = temp;
对a[2]进行操作:
现将a[2]的数据备份到temp,再开始进行比较:若a[1]>temp,则执行
a[2] = a[1];
再与a[0]进行比较:若a[0]>temp,则执行
a[1] = a[0];
最后因为已与前面所有的数都比较了,所以执行:
a[0] = temp;
总结插入排序的一个2层嵌套for循环(以升序为例)
int a[arrayLenth]; int temp; for(int i = 1;i<arrayLenth,i++) { temp = a[i]; for(int j = i;j>0&&a[j-1]>temp;j–) a[j] = a[j-1]; a[j] = temp; }
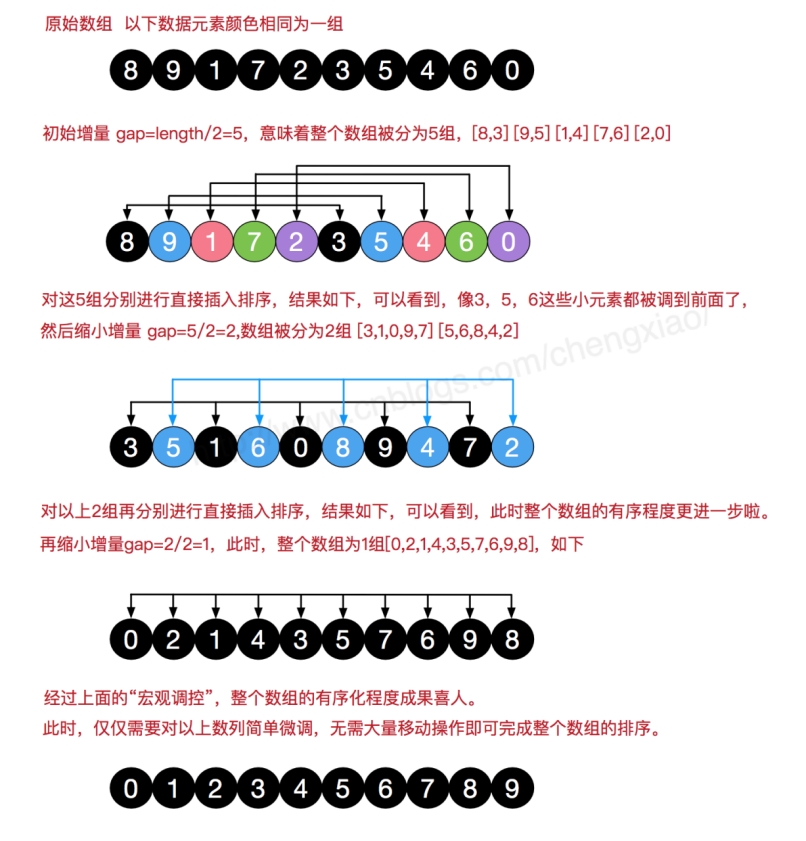
希尔排序 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
(可以简单点理解:希尔排序排序的方法还是插入排序,但是不是直接对整体一个一个进行插入排序,而是分组进行插入排序)
【个人理解】
希尔排序相对于插入排序的优势在于:
当需要进行排序的数据有较多的反序,希尔排序的交换数据次数会较少
当需要排序的数据较多时,希尔排序的交换数据次数也较少,排序时间也更短
如论如何,希尔排序的交换数据次数总小于等于插入排序。
缺点在于:
当数据较少时,希尔排序会花费更长的时间,因为此算法嵌套for循环层数过多。
下面我将利用Java作为平台去验证我对两种算法的理解:
测试代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import sun.reflect.generics.tree.VoidDescriptor;import java.util.Arrays;public class SortTest { static int NUMBER = 1000 ; static int MAX = 200 ; public static void main (String[] args) { int [] a = new int [NUMBER]; for (int i = 0 ;i < NUMBER;i++) a[i] = (int )(Math.random()*100 ); int [] b = a.clone(); insertionSort(a); System.out.println("======================================" ); ShellSort(b); } static void insertionSort (int [] a) { System.out.println(Arrays.toString(a)); int num = 0 ; long startTime = System.nanoTime(); for (int i = 1 ;i < a.length;i++){ int temp = a[i]; int j; for (j = i;(j > 0 )&&(a[j-1 ]<temp);j--) { a[j] = a[j - 1 ]; num++; } a[j] = temp; } long endTime = System.nanoTime(); System.out.println(Arrays.toString(a)); System.out.println("InsertionSort RunTime = " +(endTime-startTime)+"ns" ); System.out.println("Exchange:" +num+" times" ); } static void ShellSort (int [] a) { System.out.println(Arrays.toString(a)); int num = 0 ; long startTime = System.nanoTime(); for (int increment = a.length/2 ;increment > 0 ;increment/=2 ) for (int i = increment;i<a.length;i++){ int temp = a[i]; int j; for (j = i;j>=increment;j-=increment) if (temp > a[j-increment]) { a[j] = a[j - increment]; num++; } else break ; a[j] = temp; } long endTime = System.nanoTime(); System.out.println(Arrays.toString(a)); System.out.println("SheelSort Runtime = " +(endTime-startTime)+"ns" ); System.out.println("Exchange:" +num+" times" ); } }
测试结果:
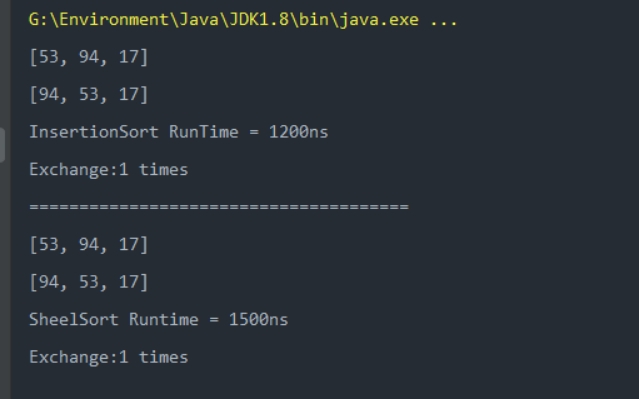
排序长度为3的随机数组
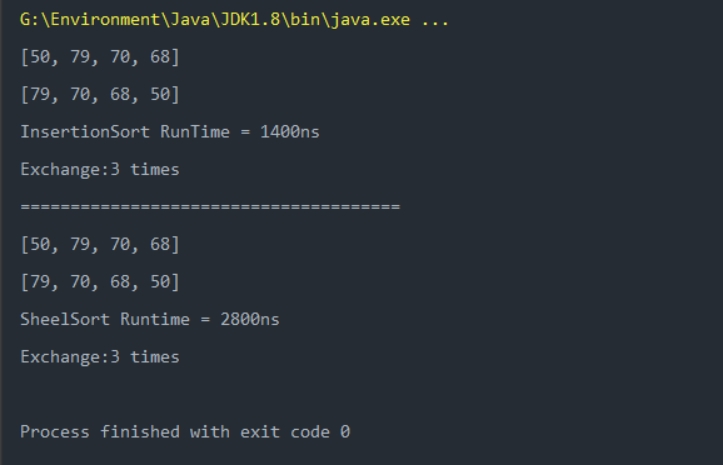
排序长度为4的随机数组:
排序长度为5的随即数组:
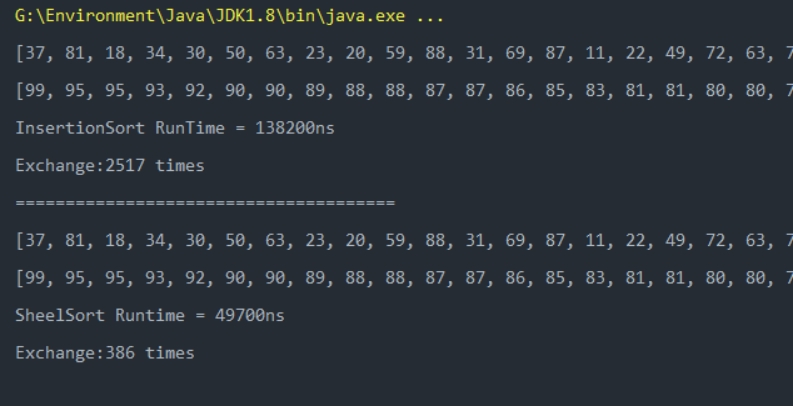
排序长度为100的随机数组:
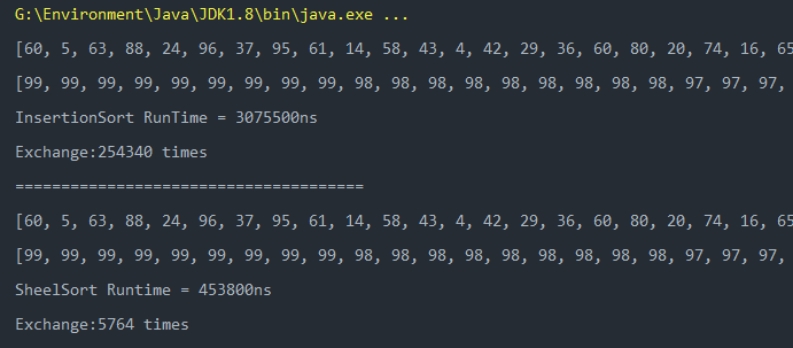
排序长度为1000的随机数组:
可以看到当需要排序的数据较少时,虽然希尔排序的数据交换次数总是小于等于插入排序,但是希尔排序的执行时间会更长;而数据较多时,希尔数据无论是交换次数还是执行时间普遍都要少于插入排序。但是在工程中的数据处理中,数据普遍较多,所以希尔排序会比插入排序更适用。